Sequential 3D Affordance Reasoning
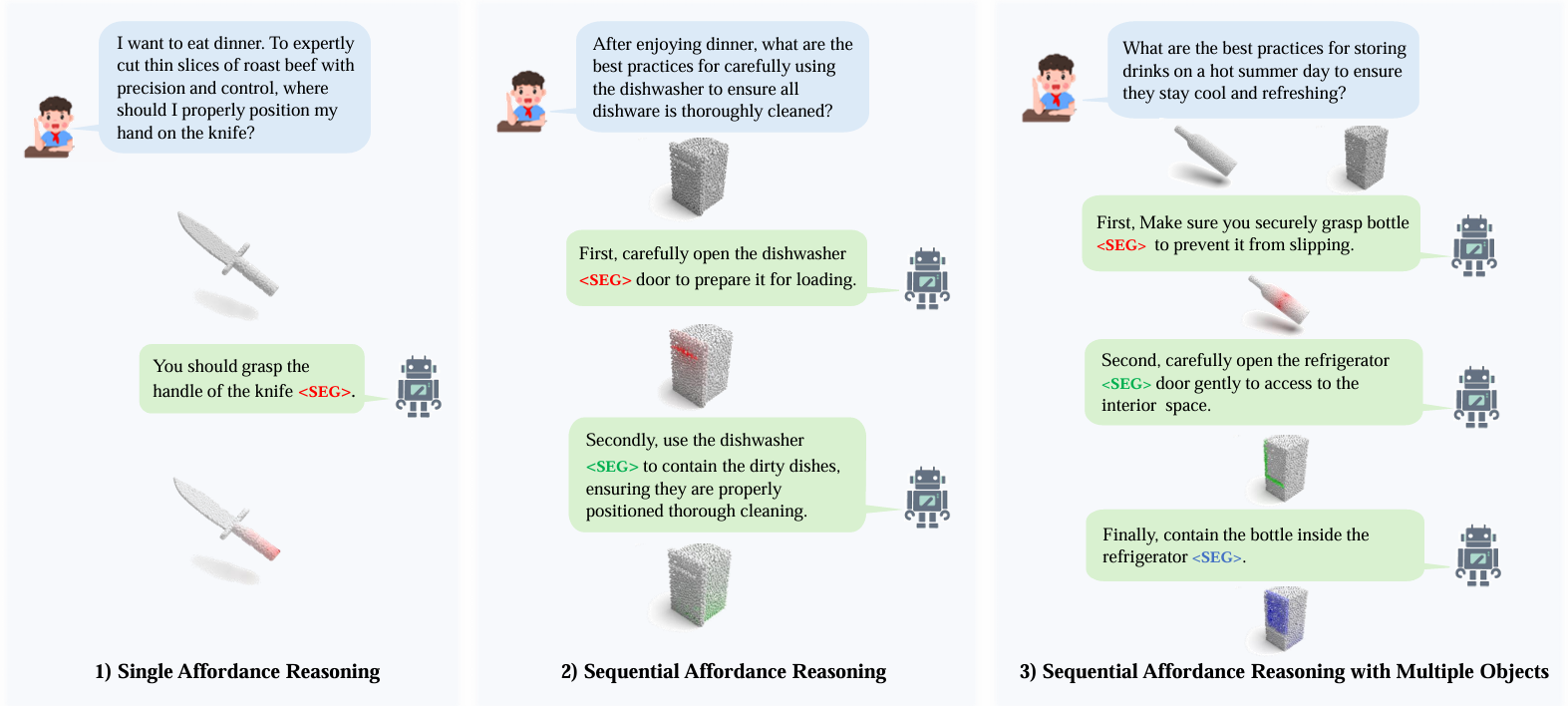
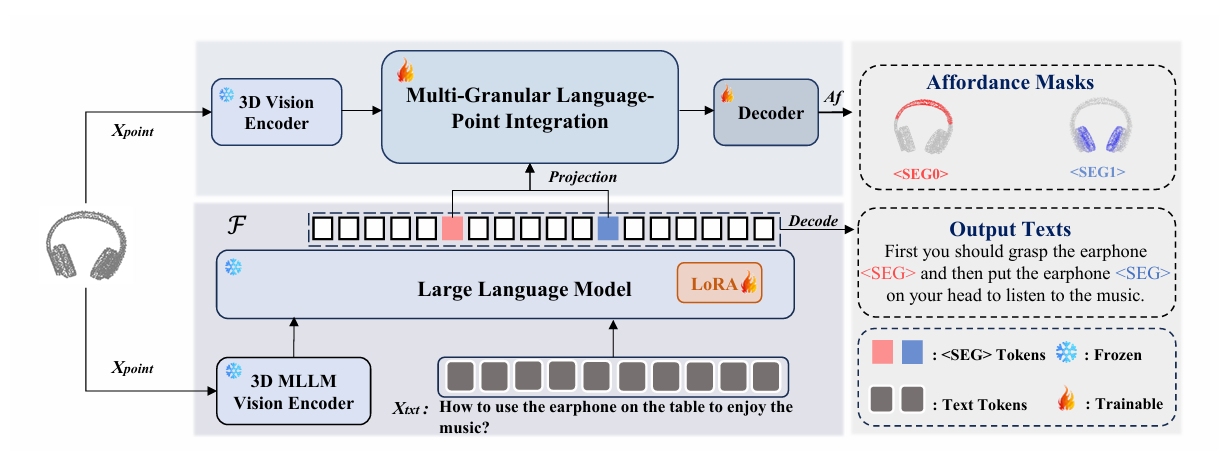
We introduce SeqAfford, a Multi-Modal Language Model (MLLM) capable of serialized affordance inference implied in human instructions: 1) Single Affordance Reasoning; 2) Sequential Affordance Reasoning; 3) Sequential Affordance Reasoning with Multiple Objects